
crawling_nlp_model_with_Django
Updated:
내가 입력한 댓글, ‘좋아요’를 평균이상 받을까?
-
어떤 글을 입력하고 얼마의 시간이 지났을 때 평균이상의 좋아요를 받을 수 있을까?
-
웹에서 데이터를 수집하고 모델학습에 예측까지 할 수 있도록 구현해 보았다
-
웹은 Django를 사용해서 구현하였다
목차
크롤링
키워드 입력 크롤링 수 입력
유튜브의 제목을 상위부터 크롤링 수만큼 키워드와 관련된 내용을 크롤링해서 보여준다
크롤링할때 유튜브 영상의 토큰값으로 접근하고 댓글 토큰값으로 한번더 접근해서 영상의 정보를 가져온다
영상 정보를 클릭하면 해당 영상 댓글의 문장과 날짜 좋아요수 다음 댓글 토큰을 재귀로 넘겨주면서 모두 가져온다
댓글의 댓글도 가져온다
csv 파일로 저장을 원하면 저장을 한다
전처리
특수문자 영어문자 모두제거 사이드 공백제거 좋아요가 평균이상이면 1 미만이면 0을 대입
모델링
LSTM 모델을 사용 문장과 날짜는 X값 좋아요는 y값으로 지정해서 학습
학습이 완료된 모델을 저장한다
페이지 설명
- home에서는 크롤링을 할지 모델 학습을 할지 선택할 수 있다
- 모델이 없다면 크롤링을 해서 모델학습에 사용할 수 있는 데이터를 만들수 있다
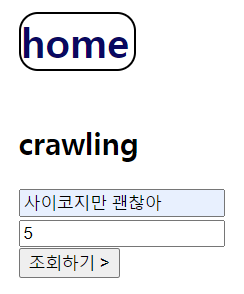
- crawling에서는 크롤링하고 싶은 키워드와 몇개 가져올지 개수를 입력한다
- title_list에서 ‘사이코지만 괜찮아’라는 키워드로 상위 5개의 영상 정보 검색해서 가져온다
- 영상이름, 영상ID, 영상업로드날짜, 좋아요/싫어요 수, 조회수, 댓글수 순서로 가져온다

- comment에는 title_list에서 하나의 영상정보를 클릭하면 그 영상이 가지고 있는 댓글을 가져온다
- 저장하기를 클릭하면 ‘검색키워드이름_댓글수.csv’로 저장한다

- model로 가면 내가 저장해서 가지고 있는 csv파일을 확인할 수 있다
- 아까 저장해던 ‘사이코지만 괜찮다_364.csv’를 확인할 수 있다
- ‘사이코지만 괜찮다_364.csv’는 데이터수(댓글수)가 작아서 학습을 통해 의미있는 모델을 만들기 힘들다
- 미리 만든 워크맨csv파일을 사용해서 모델을 학습해보자

- 여러 csv파일을 합쳐서 데이터의 양을 늘린다
- 생성될 모델의 이름을 입력하고 학습을 진행한다

- home의 model_list에서 생성된 모델을 확인할 수 있다

- 해당 모델을 클릭하면 해당 모델을 예측하는 페이지로 이동한다

- 댓글로 등록할 예상 문장을 입력하고 지날 날짜를 입력하면 예측을 한다

Leave a comment