
실습. 타이타닉 데이터 분석해보기
Updated:
csv 파일 읽고, 데이터 파악
import pandas as pd
train_data = pd.read_csv("./train.csv")
print("데이터 shape \n {}".format(train_data.shape))
print()
print("데이터 5개 미리보기 \n {}".format(train_data.head()))
print()
print("데이터 정보")
print(train_data.info())
print()
print("null값을 가지고 있는 데이터 \n {}".format(train_data.isnull().sum()))
결과값
데이터 shape
(891, 12)
데이터 5개 미리보기
PassengerId Survived Pclass \
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
4 5 0 3
Name Sex Age SibSp \
0 Braund, Mr. Owen Harris male 22.0 1
1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1
2 Heikkinen, Miss. Laina female 26.0 0
3 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1
4 Allen, Mr. William Henry male 35.0 0
Parch Ticket Fare Cabin Embarked
0 0 A/5 21171 7.2500 NaN S
1 0 PC 17599 71.2833 C85 C
2 0 STON/O2. 3101282 7.9250 NaN S
3 0 113803 53.1000 C123 S
4 0 373450 8.0500 NaN S
데이터 정보
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
null값을 가지고 있는 데이터
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
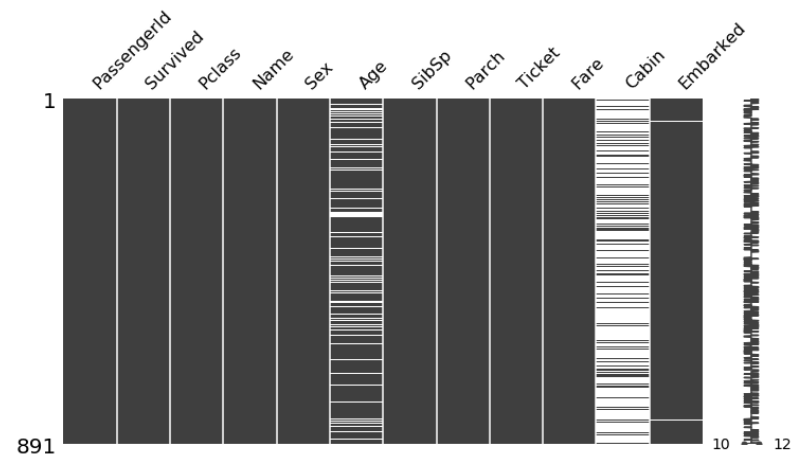
Null Data 시각화
import missingno as msno
msno.matrix(train_data, figsize=(12,6))
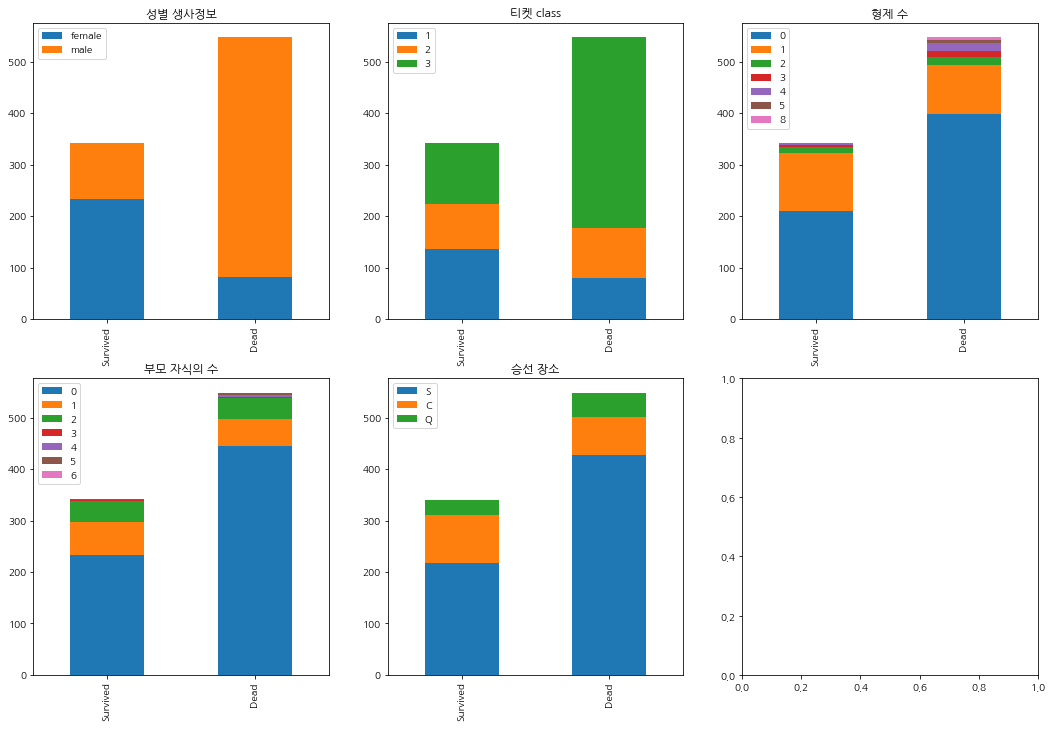
Discrete 데이터 시각화
- discrete 데이터를 bar chart로 시각화하기
import matplotlib.pyplot as plt
plt.rc('font', family='NanumGothic')
# 한글 깨짐 해결
def bar_chart(feature, ax=None):
survived = train_data[train_data['Survived']==1][feature].value_counts()
dead = train_data[train_data['Survived']==0][feature].value_counts()
df = pd.DataFrame([survived, dead])
df.index = ['Survived', 'Dead']
df.plot(kind='bar', stacked=True, ax=ax)
# stacked 가 True이면 데이터를 쌓아서 보여준다
figure, ((ax1, ax2, ax3), (ax4, ax5, ax6)) = plt.subplots(nrows=2,ncols=3)
figure.set_size_inches(18,12)
bar_chart('Sex', ax1)
bar_chart('Pclass', ax2)
bar_chart('SibSp', ax3)
bar_chart('Parch', ax4)
bar_chart('Embarked', ax5)
ax1.set(title="성별 생사정보")
ax2.set(title="티켓 class")
ax3.set(title="형제 수")
ax4.set(title="부모 자식의 수")
ax5.set(title="승선 장소")
plt.show()
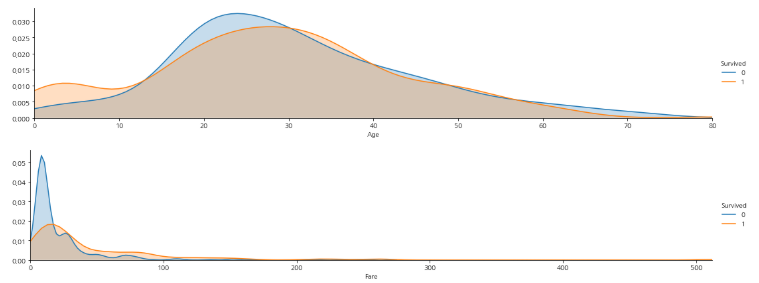
Continuous 데이터 시각화
- Continuos 데이터를 facet으로 시각화하기_1
import seaborn as sns
def draw_facetgrid(feature):
# train에 저장된 DataFrame을 FacetGrid를 통해 그래프로 그려준다
# hue="Survived"는 그래프의 범례(legend)의 이름을 설정
# aspect=5 는 그래프의 종횡비를 설정
facet = sns.FacetGrid(train_data, hue="Survived", aspect=5)
# facet.map()은 kedplot 방식을 사용하여 주어진 데이터 feature를 plotting 하는
# 즉, 그래프를 그리는 기능
facet.map(sns.kdeplot, feature, shade=True)
# 0 부터 값의 주어진 데이터의 최대 값까지를 x축의 범위로 설정
facet.set(xlim=(0, train_data[feature].max()))
# 지정된 범례(legend)를 표시
facet.add_legend()
plt.show()
draw_facetgrid('Age')
draw_facetgrid('Fare')
- 10 이하의 경우 살 확률이 크고, 10대 중반에서 30살까지는 죽을 확률이 더 큼
- 비싸게 표를 산 사람들이 살 확률이 더 높음
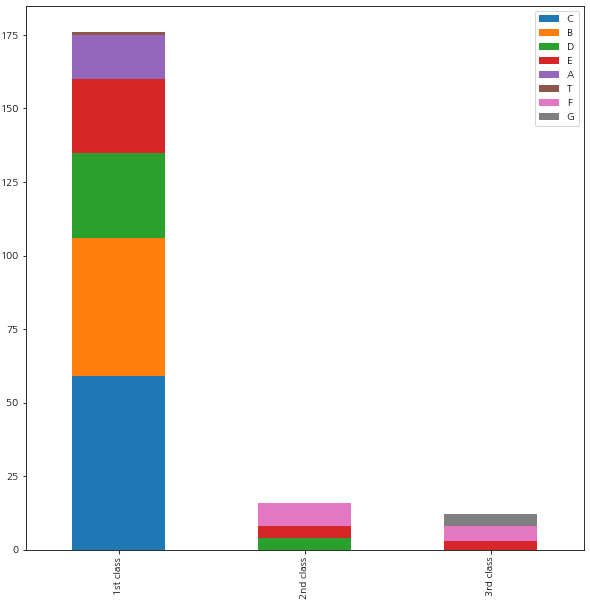
Pclass 별 cabin 형황을 시각화하기
for dataset in [train_data]:
dataset["Cabin"] = dataset["Cabin"].str[:1]
Pclass1 = train_data[train_data['Pclass']==1]['Cabin'].value_counts()
Pclass2 = train_data[train_data['Pclass']==2]['Cabin'].value_counts()
Pclass3 = train_data[train_data['Pclass']==3]['Cabin'].value_counts()
df = pd.DataFrame([Pclass1, Pclass2, Pclass3])
df.index = ['1st class', '2nd class', '3rd class']
df.plot(kind = 'bar', stacked = True, figsize=(10, 10))
Leave a comment