
실습_6. 텐서플로우
Updated:
Tensor 데이터 생성
텐서플로우는 상수, 시퀀스, 난수, 변수 등을 생성하는 연산을 제공합니다. 이러한 연산은 기존 Numpy와 유사하게 사용할 수 있습니다.
또한, 텐서플로우에는 다양한 자료형을 사용할 수 있습니다. 이를 이용하면 어떤 데이터든지 구조화된 형식으로 저장할 수 있습니다.
텐서플로우 자료형
tf.float32 : 32-bit float
tf.float64 : 64-bit float
tf.int8 : 8-bit integer
tf.int16 : 16-bit integer
tf.int32 : 32-bit integer
tf.uint8 : 8-bit unsigned integer
tf.string : String
tf.bool : Boolean
이번 실습에서는 텐서플로우의 다양한 함수와 자료형을 사용하여 직접 상수, 시퀀스, 난수, 변수 등을 생성해보도록 하겠습니다.
- 상수 텐서를 생성하는 constant_tensors 함수를 완성하세요.
- 값으로 5 를 가지는 (1,1) shape의 8-bit integer 상수 텐서를 생성하세요.
- 모든 원소 값이0인 (3 , 5) shape의 16-bit integer 텐서를 생성하세요.
- 모든 원소 값이 1인 (4 , 3) shape의 8-bit integer 텐서를 생성하세요.
- 시퀀스 텐서를 생성하는 sequence_tensors 함수를 완성하세요.
- 1.5에서 10.5까지 증가하는 3개의 텐서를 생성하세요.
- 1에서 10까지 2씩 증가하는 텐서를 생성하세요.
- 난수 텐서를 생성하는 random_tensors 함수를 완성하세요.
- 정확한 채점을 위하여 미리 설정된 seed 값을 메소드의 인자로 사용해주세요!
- 평균이 0이고 표준편차가 1인 정규 분포를 가진 (7 , 4) shape의 32-bit float 난수 텐서를 생성하세요.
- 최소값이 0이고 최대값이 3인 균등 분포를 가진 (5 , 4 , 3) shape의 32-bit float 텐서를 생성하세요.
- 변수를 생성하는 variable_tensor 함수를 완성하세요.
- 값이 100인 변수 텐서를 생성하세요.
- 실행 버튼을 눌러 결과값을 확인하고 제출해보세요.
- 텐서에 .numpy 메소드를 적용하면 numpy 배열로 변환됩니다.
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
from elice_utils import EliceUtils
import tensorflow as tf
elice_utils = EliceUtils()
def constant_tensors():
# 5의 값을 가지는 (1,1) shape의 8-bit integer 텐서를 만드세요.
t1 = tf.constant(5, dtype = tf.int8)
# 모든 원소의 값이 0인 (3,5) shape의 16-bit integer 텐서를 만드세요.
t2 = tf.zeros((3,5), dtype =tf.int16)
# 모든 원소의 값이 1인 (4,3) shape의 8-bit integer 텐서를 만드세요.
t3 = tf.ones((4,3), dtype=tf.int8)
return t1, t2, t3
def sequence_tensors():
# 1.5에서 10.5까지 증가하는 3개의 텐서를 만드세요.
seq_t1 = tf.linspace(1.5,10.5,3)
# 1에서 10까지 2씩 증가하는 텐서를 만드세요.
seq_t2 = tf.range(1,10,2)
return seq_t1,seq_t2
def random_tensors():
# 난수를 생성하기 위한 seed 값입니다.
# 정확한 채점을 위해 값을 변경하지 마세요!
seed=3921
tf.random.set_seed(seed)
# 평균이 0이고 표준편차가 1인 정규 분포를 가진 (7,4) shape의 32-bit float 난수 텐서를 만드세요.
# 정확한 채점을 위하여 미리 설정된 seed 값을 사용해주세요.
rand_t1 = tf.random.normal((7,4),mean = 0,stddev= 1,dtype=tf.float32, seed = seed)
# 최소값이 0이고 최대값이 3인 균등 분포를 가진 (5,4,3) shape의 32-bit float 난수 텐서를 만드세요.
# 정확한 채점을 위하여 미리 설정된 seed 값을 사용해주세요
rand_t2 = tf.random.uniform((5,4,3),minval = 0, maxval = 3, dtype=tf.float32, seed = seed)
return rand_t1, rand_t2
def variable_tensor():
# 값이 100인 변수 텐서를 만드세요.
var_tensor = tf.Variable(100)
return var_tensor
def main():
# 1. constant_tensors 함수를 완성하세요.
t1, t2, t3 = constant_tensors()
# 2. sequence_tensors 함수를 완성하세요.
seq_t1,seq_t2 = sequence_tensors()
# 3. random_tensors 함수를 완성하세요.
rand_t1, rand_t2 = random_tensors()
# 4. variable_tensor 함수를 완성하세요.
var_tensor = variable_tensor()
for i in [t1, t2, t3,seq_t1,seq_t2,rand_t1, rand_t2, var_tensor ]:
print(i.numpy())
if __name__ == "__main__":
main()
Tensor 연산
- 연산자
Tensorflow에도 Numpy와 유사하게 다양한 수학 연산자들을 제공합니다.
이번 실습에서는 텐서플로우의 다양한 연산자를 활용하여 텐서들의 연산을 수행해보겠습니다.
- 단항 연산자
tf.negative(x) = -x
tf.logical_not(x) = !x (tf.bool만 가능)
tf.abs(x) = x의 절대값
- 이항 연산자
tf.add(x, y) : x + y
tf.subtract(x, y) : x - y
tf.multiply(x, y) : x * y
tf.truediv(x, y) : x / y (Python 3)
- 단항 연산자를 사용해 각 변수에 저장하세요.
- 텐서 a를 음수로 변환해 neg에 저장하세요.
- 텐서 boolean를 논리적 부정값으로 변환해 logic에 저장하세요.
- 텐서 c를 절대값으로 변환해 absolute에 저장하세요.
- 이항 연산자를 사용해 사칙 연산을 수행하여 각 변수에 저장하세요.
- 텐서 a와 b 를 더해 add에 저장하세요.
- 텐서 a에서 b를 빼 sub에 저장하세요.
- 텐서 a와 b를 곱해 mul에 저장하세요.
- 텐서 a에서 b를 나눠 div에 저장하세요.
- Tensor에 .numpy 메소드를 적용하면 numpy 배열로 변환됩니다.
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
a = tf.constant(10, dtype = tf.int32)
b = tf.constant(3, dtype = tf.int32)
c = tf.constant(-10, dtype = tf.int32)
boolean = tf.constant(True, dtype = tf.bool)
# 1. 단항 연산자를 사용해보세요.
neg = tf.negative(a)
logic = tf.logical_not(boolean)
absolute = tf.abs(c)
# 2. 이항 연산자를 사용해 사칙연산을 수행해보세요.
add = tf.add(a,b)
sub = tf.subtract(a,b)
mul = tf.multiply(a,b)
div = tf.truediv(a,b)
for i in [neg, logic, absolute, add, sub, mul, div]:
print(i.numpy())
Tensorflow를 활용하여 선형회귀 구현하기
이번 실습에서는 Tensorflow를 활용하여 선형회귀를 직접 구현하여 학습 과정을 통해 가중치와 편향이 변화되는 모습을 살펴보도록 하겠습니다.
Tensorflow를 사용하기 위해서는 먼저 다음과 같이 라이브러리를 임포트해줘야합니다.
import tensorflow as tf
임포트가 완료되면 Tensorflow 내의 함수들을 사용할 수 있습니다.
앞선 2장 회귀 분석의 실습에서는 sklearn 라이브러리를 통해 선형 회귀 모델을 구현해보았지만, 이번 실습에서는 tensorflow를 활용해 선형 회귀를 직접 구현해보도록 하겠습니다.
작성되어 있는 코드들을 살펴보고 지시문에 맞게 코드를 구현하세요!
- 선형 회귀 모델 클래스 내부의 init 메소드에 W(가중치)와 b(편향)을 1.5값을 가진 변수 텐서로 설정하세요.
- 변수 텐서를 생성하는 메소드
tf.Variable(value, name)
- 선형 회귀 모델 클래스 내부의 call 메소드에 W(가중치), X, b(편향)과 tensorflow 이항 연산자 함수를 사용해 다음의 선형 모델을 구현해 반환하세요.
- y = W * X + by=W∗X+b
tf.add(tf.multiply(self.W, X),self.b)
- MSE 값을 계산해 반환하는 loss 함수를 완성하세요.
- -MSE는 mean squared error 손실 함수로, 수식은 다음과 같습니다.
tf.reduce_mean(tf.square(y - pred))
- 실행 버튼을 눌러 모델 학습에 따라 변화되는 loss 값과 가중치, 편향을 확인하고 제출하세요.
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
from elice_utils import EliceUtils
elice_utils = EliceUtils()
# 채점을 위해 랜덤 시드를 고정하는 코드입니다.
# 정확한 채점을 위해 코드를 변경하지 마세요!
np.random.seed(100)
# 선형 회귀 클래스 구현
class LinearModel:
def __init__(self):
# 1. 가중치 초기값을 1.5의 값을 가진 변수 텐서로 설정하세요.
self.W = tf.Variable(1.5)
# 1. 편향 초기값을 1.5의 값을 가진 변수 텐서로 설정하세요.
self.b = tf.Variable(1.5)
def __call__(self, X, Y):
# 2. W, X, b를 사용해 선형 모델을 구현하세요.
# y = W * X + b
return tf.add(tf.multiply(self.W, X), self.b)
# 3. MSE 값으로 정의된 loss 함수 선언
def loss(y, pred):
return tf.reduce_mean(tf.square(y - pred))
# gradient descent 방식으로 학습 함수 선언
def train(linear_model, x, y):
with tf.GradientTape() as t:
current_loss = loss(y, linear_model(x, y))
# learning_rate 값 선언
learning_rate = 0.001
# gradient 값 계산
delta_W, delta_b = t.gradient(current_loss, [linear_model.W, linear_model.b])
# learning rate와 계산한 gradient 값을 이용하여 업데이트할 파라미터 변화 값 계산
W_update = (learning_rate * delta_W)
b_update = (learning_rate * delta_b)
return W_update,b_update
def main():
# 데이터 생성
x_data = np.linspace(0, 10, 50)
y_data = 4 * x_data + np.random.randn(*x_data.shape)*4 + 3
# 데이터 출력
plt.scatter(x_data,y_data)
plt.savefig('data.png')
elice_utils.send_image('data.png')
# 선형 함수 적용
linear_model = LinearModel()
# epochs 값 선언
epochs = 100
# epoch 값만큼 모델 학습
for epoch_count in range(epochs):
# 선형 모델의 예측 값 저장
y_pred_data=linear_model(x_data, y_data)
# 예측 값과 실제 데이터 값과의 loss 함수 값 저장
real_loss = loss(y_data, linear_model(x_data, y_data))
# 현재의 선형 모델을 사용하여 loss 값을 줄이는 새로운 파라미터로 갱신할 파라미터 변화 값을 계산
update_W, update_b = train(linear_model, x_data, y_data)
# 선형 모델의 가중치와 편향을 업데이트합니다.
linear_model.W.assign_sub(update_W)
# linear_model.W -= update_W
linear_model.b.assign_sub(update_b)
# linear_model.b -= update_b
# 20번 마다 출력 (조건문 변경 가능)
if (epoch_count%20==0):
print(f"Epoch count {epoch_count}: Loss value: {real_loss.numpy()}")
print('W: {}, b: {}'.format(linear_model.W.numpy(), linear_model.b.numpy()))
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.scatter(x_data,y_data)
ax1.plot(x_data,y_pred_data, color='red')
plt.savefig('prediction.png')
elice_utils.send_image('prediction.png')
if __name__ == "__main__":
main()
Tensorflow와 Keras를 활용하여 비선형회귀 구현하기
이번 실습에서는 Tensorflow와 Keras를 활용하여 Fully connected 모델, 즉 다층 퍼셉트론을 직접 생성해보겠습니다.
Keras는 Tensorflow 내의 딥러닝 모델 설계와 훈련을 위한 API 입니다. 케라스는 Sequential하게 계층 (Layer)들을 쌓아가며 모델을 생성하고 사이킷런과 같이 한 줄의 코드로 간단하게 학습 방법 설정, 학습, 평가를 진행할 수 있습니다.
.keras.models.Sequential() : 인공 신경망 Sequential 모델을 만들기 위한 함수
model.complie() : 학습 방법 설정
model.fit() : 모델 학습
model.predict() : 학습된 모델로 예측값 생성
keras.layers.Dense(units,activation)
신경망 모델의 layer를 구성하는데 필요한 keras 함수로 units는 레이어 안의 Node의 수를 의미하며, activation이란 적용할 activation function을 의미합니다. 이 외에도 다양한 인자가 존재하는데 추가적인 인자에 대한 정보는 아래 링크를 통해 확인할 수 있습니다.
keras.layers.Dense 함수의 추가 인자 확인하기
- Seuential 모델 안의 내부 인자로 Dense 함수를 이용하여 여러 층의 layer를 쌓아 인공 신경망 모델을 생성할 수 있습니다. tf.keras.models.Sequential 내에tf.keras.layers.Dense() 함수를 이용하여 아래 신경망 모델을 생성하세요.
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(20, input_dim = 1 ,activation='relu'),
tf.keras.layers.Dense(20, activation='relu'),
tf.keras.layers.Dense(1)
])
- 첫 번째 layer(Input layer):
입력되는 데이터의 차원에 따라 input_dim에 적절한 값을 설정해주어야 합니다. 여기서 dim이란 dimension, 즉 차원을 의미합니다.
- 마지막 Layer(Output layer):
출력해야 하는 결과값의 개수만큼 노드의 개수를 설정해주어야 합니다.
- 모델을 학습시킬 손실함수(loss) 계산 방법과 최적화(optimizer) 방법을 다음과 같이 설정합니다.
- 손실함수(loss) : ‘mean_squared_error’
- 최적화 방법(optimizer) : ‘adam’
model.compile(loss='mean_squared_error', optimizer='adam')
- 생성한 모델을 500 epochs 만큼 학습시킵니다. verbose 인자에는 0,1,2 값을 설정할 수 있으며, 이는 모델 학습 과정 정보를 얼마나 자세하게 출력할지를 설정합니다.
model.fit(x_data, y_data, epochs=500, verbose=2)
- 학습한 모델을 사용하여 x_data에 대한 예측값을 생성하고 이를 predictions에 저장합니다.
predictions = model.predict(x_data)
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
from elice_utils import EliceUtils
elice_utils = EliceUtils()
from mpl_toolkits.mplot3d import Axes3D
# 채점을 위한 코드입니다.
# 정확한 채점을 위해 코드를 수정하지 마세요!
np.random.seed(100)
tf.random.set_seed(100)
# 데이터 생성
x_data = np.linspace(0, 10, 100)
y_data = 1.5 * x_data**2 -12 * x_data + np.random.randn(*x_data.shape)*2 + 0.5
# 1. 신경망 모델 생성
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(20, input_dim=1, activation='relu'),
tf.keras.layers.Dense(20, activation = 'relu'),
tf.keras.layers.Dense(1)
])
# 모델 복잡도 체크
print(model.summary())
# 2. 모델 학습 방법 설정
model.compile(loss='mean_squared_error', optimizer='adam')
# 3. 모델 학습
model.fit(x_data, y_data, epochs=500, verbose=2)
# 4. 학습된 모델을 사용하여 예측값 생성 및 저장
predictions = model.predict(x_data)
# 데이터 출력
plt.scatter(x_data,y_data)
plt.savefig('data.png')
elice_utils.send_image('data.png')
# 곡선형 분포 데이터와 예측값 출력
plt.scatter(x_data,predictions, color='red')
plt.savefig('prediction.png')
elice_utils.send_image('prediction.png')
다중 선형 회귀분석 인공 신경망으로 구현하기
앞선 2장 회귀 분석에서 Advertising.csv 데이터를 활용하여 다음의 모델을 구현하는 다중 선형 회귀분석 실습을 진행해보았습니다.
이번 실습에서는 sklearn 라이브러리를 이용하여 구현한 다중 선형 회귀분석을 동일한 데이터를 사용하여 직접 여러 Layer를 쌓아가며 MSE 값을 1 이하로 낮출 수 있는 인공 신경망 모델로 구현해보겠습니다.
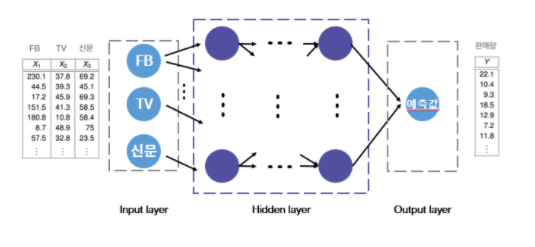
X,Y는 ./data/Advertising.csv 데이터를 읽고 만든 데이터입니다. X는 (200, 3) shape을 가진 2차원 np.array로 , TV, Newspaper Column에 해당하는 데이터가 저장됩니다. Y는 (200,) 의 shape을 가진 1차원 np.array로 Sales Column에 해당하는 데이터가 저장됩니다.
X = [[ 230.1 37.8 69.2]
[ 44.5 39.3 45.1]
[ 17.2 45.9 69.3]
[ 151.5 41.3 58.5]
...
Y = [ 22.1 10.4 9.3 18.5 ...
- sklearn에서 제공하는 train_test_split 메소드를 활용하여 X, Y 데이터를 8:2 비율로 학습용과 테스트용 데이터로 분리하여 각각 x_train, x_test, y_train, y_test에 저장합니다.
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
- FB, TV, Newspaper의 값에 따라 예상되는 Sales 값을 예측하는 인공 신경망 모델을 생성합니다. MSE 값을 1 이하로 낮추는 모델을 생성하세요.
- 예측값과 실제 데이터의 loss인 MSE 값을 1이하로 낮출 수 있도록 Input Layer와 Output Layer 사이에 여러 층의 hidden layer를 추가해보세요.
- Tip! 여러 층의 hidden layer를 추가하여 모델을 구성하면 모델의 성능을 향상시킬 수 있습니다.
- 생성한 인공신경망 모델의 MSE 값을 1 이하로 낮출 수 있도록 epochs 값을 설정하세요.
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
import numpy as np
import random
from data import *
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# seed를 고정하는 코드입니다.
# 정확한 채점을 위하여 코드를 변경하지 마세요!
tf.random.set_seed(123)
np.random.seed(123)
# advertising.csv 데이터가 X와 Y에 저장됩니다.
# X는 (200, 3) 의 shape을 가진 2차원 np.array,
# Y는 (200,) 의 shape을 가진 1차원 np.array 입니다.
# X는 FB, TV, Newspaper column 에 해당하는 데이터,
# Y는 Sales column 에 해당하는 데이터가 저장됩니다.
X,Y = read_data()
# 1. 학습용 데이터와 테스트용 데이터로 분리합니다.(80:20)
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
# 2. MSE 값을 1 이하로 낮추는 모델 구현하기
# 2-1. 인공신경망 모델 구성하기
model = tf.keras.models.Sequential([
# Input Layer
tf.keras.layers.Dense(20, input_dim = 3, activation='relu'),
# MSE 값을 1 이하로 낮출 수 있도록 여러 층의 hidden layer를 추가해보세요.
##########################################################
tf.keras.layers.Dense(20, activation='relu'),
##########################################################
# Output Layer
tf.keras.layers.Dense(1)
])
# 모델 학습 방법 설정
model.compile(loss= 'mean_squared_error',
optimizer='adam')
# 2-2. epochs 값 설정 후 모델 학습
model.fit(x_train, y_train, epochs=500)
# 학습된 신경망 모델을 사용하여 예측값 생성 및 loss 출력
predicted = model.predict(x_test)
mse_test = mean_squared_error(predicted, y_test)
print("MSE on test data: {}".format(mse_test))
네이버 영화평 감정분석 인공 신경망으로 구현하기
앞선 3장 나이브 베이즈 분류에서는 실제 영화 리뷰를 이용해 나이브 베이즈 분류기를 학습시키고, 입력 받은 영화평이 긍정 또는 부정적일 확률을 구하는 감정 분석(Sentiment Analysis)을 진행해보았습니다.
이번 실습에서는 동일한 데이터를 사용하여 인공 신경망을 학습시켜 감정 분석을 구현해보겠습니다.
원본 데이터는 총 100,000개의 부정 리뷰, 100,000개의 긍정 리뷰로 구성되어 있으나, 해당 실습에서는 랜덤하게 추출한 100개의 긍,부정 데이터를 사용합니다.
id, document, label은 각각 사용자 아이디(정수), 리뷰 본문(문자열), 긍정·부정(1·0)을 나타내며 탭(\t)으로 나누어져 있습니다.
id document label
9251303 와.. 연기가 진짜 개쩔구나.. 지루할거라고 생각했는데 몰입해서 봤다.. 그래 이런게 진짜 영화지 1
10067386 안개 자욱한 밤하늘에 떠 있는 초승달 같은 영화. 1
2190435 사랑을 해본사람이라면 처음부터 끝까지 웃을수 있는영화 1
데이터 출처 : 네이버 개발자 Lucy Park님의 Naver Sentiment Movie Corpus v1.0
- ‘ratings.txt’ 파일에서 데이터를 읽어 저장하는 read_data() 함수를 구현합니다. read_data() 함수는 sentences 와 labels 라는 두개의 리스트를 반환합니다.
- 첫번째 리스트 sentences 에는 다음과 같이 리뷰 본문들을 저장합니다. 리뷰 본문들에는 특수 문자를 제거한 문자열들이 저장되어야 합니다.
sentences = ['어이 없어서 10점 준다.','세련된 헐리우드 블록버스터',...]
- 두번째 리스트 labels에는 해당 리뷰 문장의 긍정,부정(1 or 0) 값을 정수형으로 저장합니다.
labels = [0,1,...]
- 리뷰 문장들을 인공신경망에 입력하기 위한 카운트 벡터로 변환해 반환하는 count_vect 함수를 구현합니다.
sklearn에서는 자연어 전처리를 위해 다양한 함수를 제공하고 있는데, 그 중 CountVectorizer는 게시물마다 등장하는 단어의 빈도수를 파악해 하나의 카운트 벡터로 만들어줍니다. 인자인 min_df 는 설정한 값보다 작은 빈도수를 가진 단어는 제외하여 카운트 벡터를 생성합니다.
Vectorizer = CountVectorizer(min_df=1)
vector = Vectorizer.fit_transform(sentences)
vector = vector.toarray()
- 구현된 인공신경망 모델을 살펴보고, 손실함수(loss)와 최적화 방법(optimizer)를 다음과 같이 설정하세요.
- loss: ‘sparse_categorical_crossentropy’
- optimizer : ‘adam’
- 행 버튼을 눌러 테스트 문장에 대한 결과값을 확인하고 제출하세요.
import io
import matplotlib as mpl
mpl.use("Agg")
import logging
logging.getLogger('tensorflow').disabled = True
import matplotlib.pyplot as plt
import numpy as np
import re
import math
import tensorflow as tf
import random
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
from sklearn.feature_extraction.text import CountVectorizer
import elice_utils
elice_utils = elice_utils.EliceUtils()
# seed를 고정하는 코드입니다.
# 정확한 채점을 위하여 값을 변경하지 마세요!
tf.random.set_seed(123)
np.random.seed(123)
special_chars_remover = re.compile("[^\w'|_]")
# 특수 문자를 제거하는 함수입니다.
def remove_special_characters(sentence):
return special_chars_remover.sub(' ', sentence)
# 1. /data/ratings.txt 에서 데이터를 읽어, 인공신경망 학습을 위한 두 개의 리스트를 반환합니다.
def read_data():
sentences = []
labels = []
with open('data/ratings.txt') as fp:
next(fp)
for line in fp:
dp = line.split('\t')
sentences.append(remove_special_characters(dp[1]))
labels.append(int(dp[2]))
return sentences,labels
# 2. count_vect 함수를 완성하세요.
def count_vect(sentences, testing_sentence):
# 테스트 문장 또한 토큰 빈도수 안에 포함되어야하기 때문에 sentences 리스트에 추가합니다.
sentences.append(testing_sentence)
# sentences를 카운트 벡터로 변환하세요.
Vectorizer = CountVectorizer(min_df=1)
vector = Vectorizer.fit_transform(sentences)
vector = vector.toarray()
return vector
# ANN 함수를 완성하세요.
def ANN(vector,labels):
# 카운트 벡터로 변환된 테스트 문장 벡터를 저장합니다.
test = vector[-1]
# 모델 학습 데이터에서 테스트 데이터를 제거합니다.
vector = vector[:-1]
# 모델 입력을 위한 형태로 변환합니다.
test = [[test]]
# 입력 데이터의 차원은 카운트 벡터 안의 토큰 수 입니다.
num_voca = len(vector[0])
# 인공 신경망 생성
ANN_model = tf.keras.models.Sequential([
tf.keras.layers.Dense(20, input_dim = num_voca, activation='relu'),
tf.keras.layers.Dense(20, activation='relu'),
tf.keras.layers.Dense(2,activation='softmax')
])
# 3. loss와 optimizer를 설정하세요.
ANN_model.compile(loss= 'sparse_categorical_crossentropy',
optimizer= 'adam')
# 학습 시작
ANN_model.fit(vector, labels , epochs=500, verbose=0)
predict = ANN_model.predict(test)
return predict
def main():
train_sentences,labels = read_data()
testing_sentence = "어설픈 연기들로 몰입이 전혀 안되네요"
bow_vect = count_vect(train_sentences, testing_sentence)
probs = ANN(bow_vect,labels)
# 시각화 코드입니다.
plot_title = testing_sentence
if len(plot_title) > 50: plot_title = plot_title[:50] + "..."
visualize_boxplot(plot_title,
[probs[0][0],probs[0][1]],
['Negative', 'Positive'])
def visualize_boxplot(title, values, labels):
width = .35
print(title)
fig, ax = plt.subplots()
ind = np.arange(len(values))
rects = ax.bar(ind, values, width)
ax.bar(ind, values, width=width)
ax.set_xticks(ind + width/2)
ax.set_xticklabels(labels)
def autolabel(rects):
# attach some text labels
for rect in rects:
height = rect.get_height()
ax.text(rect.get_x()+rect.get_width()/2., height + 0.01, '%.2lf%%' % (height * 100), ha='center', va='bottom')
autolabel(rects)
plt.savefig("image.svg", format="svg")
elice_utils.send_image("image.svg")
if __name__ == "__main__":
main()
Fashion-MNIST 데이터 분류하기
Fashion-MNIST 데이터란 의류, 가방, 신발 등의 패션 이미지들의 데이터셋으로 60,000개의 학습 데이터 셋과 10,000개의 테스트 데이터 셋으로 이루어져 있습니다.
각 이미지들은 (28x28) 크기의 흑백 이미지로, 총 10개의 클래스로 분류되어 있습니다.
이번 실습에서 사용하는 데이터는 모델 학습을 위해 (28x28) 크기의 다차원 데이터를 1차원 배열로 전처리한 데이터로, 60,00개의 학습 데이터 중 4,000개의 학습 데이터와 10,000개의 테스트 데이터 중 1,000개의 데이터를 랜덤으로 추출하였습니다.
이번 실습에서는 이러한 Fashion-MNIST 데이터를 각 이미지의 레이블에 맞게 분류하는 인공 신경망을 생성해보고, 모델의 성능인 Test 데이터에 대한 정확도를 86% 이상으로 높여보도록 하겠습니다.

출처 : https://research.zalando.com/welcome/mission/research-projects/fashion-mnist/
- Fashion-MNIST 데이터 분류를 위한 인공 신경망을 생성하고, 학습 방법을 설정해 학습시킨 모델을 반환하는 ANN_classifier() 함수를 구현하세요.
- 인공 신경망 분류 모델을 생성합니다. 여러 층의 layer를 쌓아 모델을 구성해보세요.
- 첫 번째 레이어(Input layer)
이번 실습에서 사용하는 데이터는 이미 전처리 되어 있기 때문에 input_dim 인자를 통해 데이터의 크기를 맞춰주지 않아도 됩니다.
tf.keras.layers.Dense(64, activation='relu')
- 마지막 레이어(Output layer)
10개 클래스에 대한 확률을 출력
tf.keras.layers.Dense(10, activation='softmax')
- model 을 학습시킬 optimizer와 loss를 다음과 같이 설정합니다.
-
loss: ‘sparse_categorical_crossentropy’
-
optimizer : ‘adam’
- 학습할 epochs 값을 설정하여 train 데이터에 대한 학습을 진행합니다.
- 실행 버튼을 눌러 Test 데이터에 대한 모델의 성능 즉, Test 정확도를 확인하고 86% 이상으로 높여 제출해보세요.
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import random
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import elice_utils
eu = elice_utils.EliceUtils()
# seed를 고정하는 코드입니다.
# 정확한 채점을 위하여 값을 변경하지 마세요!
np.random.seed(100)
tf.random.set_seed(100)
def ANN_classifier(x_train, y_train):
# 1-1. 인공 신경망 분류 모델을 생성합니다.
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# 1-2. 모델을 학습할 loss와 optimizer를 설정합니다.
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 1-3. 모델을 학습할 epochs 값을 설정합니다.
model.fit(x_train, y_train, epochs=100)
return model
def main():
x_train = np.loadtxt('./data/train_images.csv', delimiter =',', dtype = np.float32)
y_train = np.loadtxt('./data/train_labels.csv', delimiter =',', dtype = np.float32)
x_test = np.loadtxt('./data/test_images.csv', delimiter =',', dtype = np.float32)
y_test = np.loadtxt('./data/test_labels.csv', delimiter =',', dtype = np.float32)
# 이미지 데이터를 0~1범위의 값으로 바꾸어 줍니다.
x_train, x_test = x_train / 255.0, x_test / 255.0
model = ANN_classifier(x_train,y_train)
# 학습한 모델을 test 데이터를 활용하여 평가합니다.
loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print('\n- TEST 정확도 :', test_acc)
# 임의의 3가지 test data의 이미지와 레이블값을 출력하고 예측된 레이블값 출력
predictions = model.predict(x_test)
rand_n = np.random.randint(100, size=3)
for i in rand_n:
img = x_test[i].reshape(28,28)
plt.imshow(img,cmap="gray")
plt.show()
plt.savefig("test.png")
eu.send_image("test.png")
print("Label: ", y_test[i])
print("Prediction: ", np.argmax(predictions[i]))
if __name__ == "__main__":
main()
Leave a comment