
6장. 텐서플로우
Updated:
텐서플로우(Tensorflow)
- 유연하고, 효율적이며, 확장성이 있는 딥러닝 프레임워크 대형 클러스터 컴퓨터부터 스마트폰까지 다양한 디바이스에서 동작
- 지원하는 언어 : Python 2/3, C/C++ 등
텐서(Tensor)
- Tensor = Multidimensional Arrays = Data
- 딥러닝에서 텐서는 다차원 배열로 나타내는 데이터 예를 들어, RGB 이미지는 삼차원 배열로 나타나는 텐서
플로우(Flow)
- 플로는 데이터의 흐름을 의미 텐서플로우에서 계산은 데이터 플로우 그래프로 수행 그래프를 따라 데이터가 노드를 거쳐 흘러가면서 계산
텐서 + 플로우
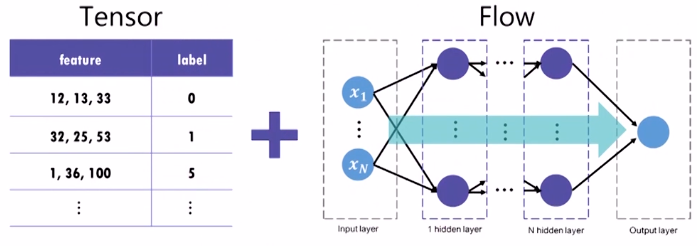
- 딥러닝에서 데이터를 의미하는 텐서(tensor)와 데이터 플로우 그래프를 따라 연산이 수행되는 형태(Flow)의 합
텐서플로우 사용법
상수 선언 하기
- value: 반환되는 상수값
- shape: Tensor의 차원 => tuple의 형식으로 입력한다
- dtype: 반환되는 Tensor 타입
- name: 상수 이름
import tensorflkow as tf
# 상수형 텐서 선언
tensor_a = tf.constant(value, dtype=None, shape=None, name=None)
# 모든 원소 값이 0인 Tensor 생성
tensor_b = tf.zeros(shape, dtype=tf.float32, name=None)
# 모든 원소 값이 1인 Tensor 생성
tensor_c = tf.ones(shape, dtype=tf.float32, name=None)
시퀀스 선언 하기
- start: 시작 값
- stop: 끝 값
- num: 생성할 데이터 개수
- delta: 증가량
- name: 시퀀스 이름
import tensorflow as tf
# start에서 stop까지 증가하는 num 개수 데이터
tensor_d = tf.linspace(start, stop, num, name=None)
# start에서 stop까지 delta씩 증가하는 데이터
tensor_e = tf.range(start, limit=None, delto=None, name=None)
난수 선언 하기
import tensorflow as tf
# 정규 분포 생성
tensor_f = tf.random.normal(shaape, mean = 0.0, stddev=1.0, dtype=tf.float32, seed=None, name='normal')
# 균증분포 생성
tf.random.uniform(shape, minval=0, maxval=None, dtype=tf.float32, seed=None, name='uniform')
변수 선언 하기
import tensorflow as tf
# 정규분포 생성
tensor_f = tf.Variable(value, name=None)
# 일반적인 퍼셉트론의 가중치와 bias 생성
weight = tf.Variable(10)
bias = tf.Variable(tf.random.normal([10,10]))
텐서 연산자
import tensorflow as tf
# 단항 연산자
tf.negative(x) # -x x가 숫자일때
tf.logical_not(x) # !x x가 boolean일때
tf.abs(x) # x의 절대값
# 이항 연산자
tf.add(x,y) # x + y
tf.subtract(x,y) # x - y
tf.multiply(x,y) # x * y
tf.truediv(x,y) # x / y
tf.math.mod(x,y) # x % y
tf.math.pow(x,y) # x ** y
딥 러닝 구현
- Epoch: 한번의 epoch는 전체 데이터 셋에 대해 한 번 학습을 완료한 상태
- Batch: batch(보톤 mini-batch라고 표현)는 나눠진 데이터 셋을 뜻하며 iteration는 epoch를 나누어서 실행하는 횟수
데이터 준비
import tensorflow as tf
import numpy as np
data = np.random.sample((100,2))
labels = np.random.sample((100,1))
# numpy array로부터 데이터셋 생성
dataset = tf.data.Dataset.from_tensor_slices((data,labels))
dataset = dataset.batch(32)
- Dataset API를 사용하여 딥러닝 모델 용 dataset을 생성
karas
-
keras는 딥러닝 모델을 만들기 위한 고수준의 API 요소를 제공하는 모델 수준의 라이브러리
-
karas API
- 동일한 코드로 CPU와 GPU에서 실행
- 사용하기 쉬운 API를 가지고 있어 딥러닝 모델의 프로토타입을 빠르게 구현
- 합성곱 신경망, 순환 신경망을 지원하면 이 둘을 자유롭게 조합하여 가능
- MIT 라이선스를 따르므로 상업적인 프로젝트에도 자유롭게 사용할 수
딥러닝 모델 생성 함수
- 인공신경망 모델을 만들기 위한 함수
tf.keras.models.Sequential()
- 신경망 모델의 layer 구성에 필요한 함수
tf.keras.layers.Dense(units, activation)
- units: 레이어 안의 Node의 수
- activation: 적용할 activation 함수
딥러닝 모델 구축
import tensorflow as tf
model = tf.keras.models.sequential([
tf.keras.layers.Dense(10, input_dim=2, activation='sigmoid'),
tf.keras.layers.Dense(10, activation = 'sigmoid')
tf.keras.layers.Dense(1, activation= 'sigmoid')
])
- tf.keras.layers를 추가하여 hidden layer를 쌓음
딥러닝 모델 학습 및 평가
model.compile(loss='mean_squared_error', optimizer='SGD')
model.fit(dataset, epochs=100)
dataset_test = tf.data.Dataset.from_tensor_slices((data_test, labels_test))
dataset_test = dataset.batch(32)
model.evaluate(dataset_test)
predicted_labels_test = model.predict(data_test)
Leave a comment