
데이터시각화
Updated:
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
# 한글을 사용하고 싶을때 사용할 수 있는 과정
#data = pd.read_csv('Traffic_Accident_2017.csv', encoding = 'euc-kr')
data = pd.read_csv(r'c:/Users/user/Desktop/인공지능사관/2주차/머신러닝/Traffic_Accident_2017.csv', encoding = 'euc-kr')
#data.info() => data 관련 정보
data.T
# data.T 행 열 반전
t = data['요일'].value_counts()
# 단일 값을 가져오는 법
t[['월','화','수','목','금','토','일']]
# 부분부분 가져올수 있는 팬시 인덱싱
# 범위로 가져오는법 # boolean 인덱싱 true만 값을 가져오는 법도 있다.
y = t[['월','화','수','목','금','토','일']]
x = ['월','화','수','목','금','토','일']
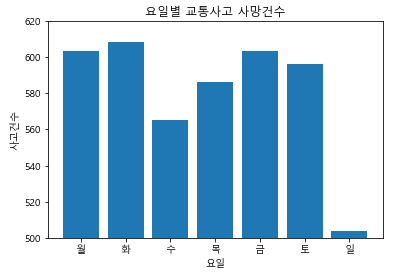
plt.ylim(500, 620)
# y축에 범위를 지정해 준다
plt.title('요일별 교통사고 사망건수')
plt.xlabel("요일")
plt.ylabel("사고건수")
plt.bar(x,y)
plt.show()
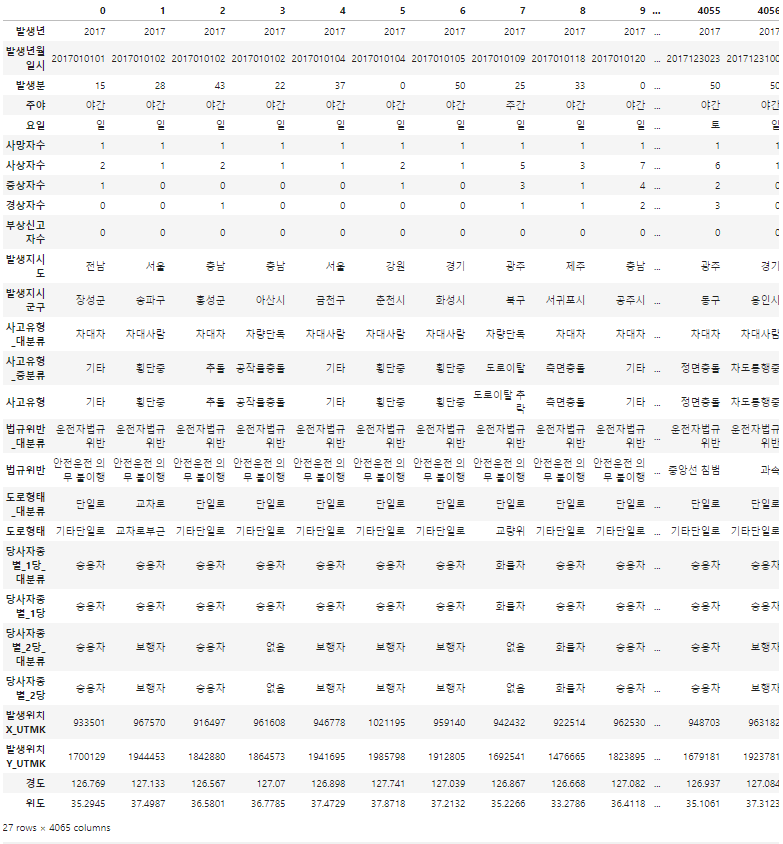
#차대차사고 시도별 사건 건수
t = data[['발생지시도','사고유형_대분류']][data['사고유형_대분류'] == '차대차']#뒤의 data는 조건이다
#data의 '사고유형_대분류가 차대차인 값만 가져온다'
print(t)
t = t['발생지시도'].value_counts()
x = t.index
y = t.values
plt.bar(x,y)
plt.show()
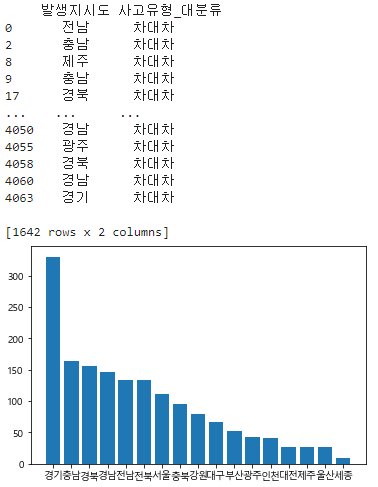
# 카테고리
ages = [0,2,10,21,23,37,31,61,20,41,32,100]
bins = [0,15,25,35,60,99]
labels = ["미성년자","청년","중년","장년","노년"]
cats = pd.cut(ages, bins, labels = labels)
cats

data['발생년월일시'] % 100
l = [x % 100 for x in data['발생년월일시']]
time_df = pd.DataFrame(l, columns = ['사고시간'])
time_df

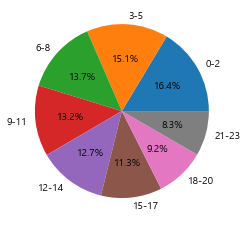
# 교통사고 다발 시간대
# 0~3~6~9... 8개의 구간으로 나누어서 사건건수
bins = [0,3,6,9,12,15,18,21,24]
labels = ["0-2","3-5","6-8","9-11","12-14","15-17","18-20","21-23"]
time_cuts = pd.cut(time_df['사고시간'],bins,labels = labels)
time_cuts.value_counts()

rs = time_cuts.value_counts()
plt.pie(rs, labels = labels, autopct = '%1.1f%%')
plt.show()
import pandas as pd
df = pd.read_excel(r'c:/Users/user/Desktop/인공지능사관/2주차/머신러닝/남북한발전전력량.xlsx')
t = df.iloc[[0,5],2:]
t.index = ["South", "North"]
t.columns = t.columns.map(int)
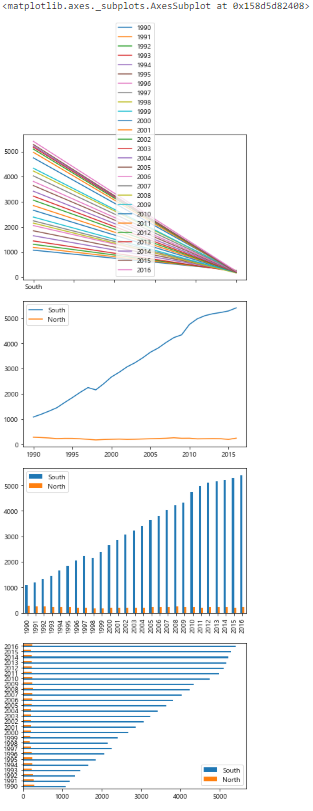
t.plot()
df_t = t. T
df_t.plot()
df_t.plot(kind='bar')
df_t.plot(kind='barh')
Leave a comment