
머신러닝 - 군집 문제
Updated:
1. 군집분석
-
비지도학습
정답이 없는 문제를 해결하기 위한 알고리즘 - 정답을 모르는 데이터 안에서 숨겨진 구조를 찾는 것
- 클래스 레이블이 없는 데이터를 특정 군집으로 묶고자 할 때 활용
2. K-평균(k-means)
- 매우 쉬운 구현성
- 높은 계산 효율성
- 산업현장, 학계에서 널리 사용
- 프로토타입 기반 군집
- 하나의 프로토타입으로 표현가능
-
프로토타입
연속적인 특성에서는 비슷한 데잍터 포인트의 센트로이드(centroid - 평균) 범주형 특성에서는 메도이드(medoid - 가장 자주 등장하는 포인트)
- 원형 클러스트를 만드는데 뛰어남
-
클러스터의 수를 직접 지정해 주어야 한다.(다소 주관적)
- 목표
- 최적화 문제
- 특성의 유사도에 기초하여 데이터들을 그룹으로 모으는 것
- 순서
- 데이터 포인트에서 랜덤하게 k개의 센트로이드를 초기 클러스터 중심으로 선택
- 각 데이터를 가장 가까운 센트로이드에 할당합니다.
- 할당된 샘플들의 중심으로 센트로이드를 이동시킵니다.
- 클러스터 할당이 변하지 않거나, 사용자가 지정한 허용오차나, 최대 반복횟수에 도달할 때까지 두번째와 세번째 과정을 반복합니다.
- 유사도
- 임의의 차원공간에서 Euclidean Dstance or Squared Euclidean Distance => 최적화 문제
- 최적화
- 클러스터 내의 제곱 오차합 (SSE)을 반복적으로 최소화
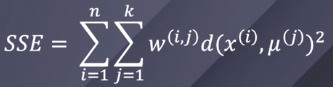
- 임의의 클러스터의 대표 센트로이드(중심)
- 측정하려는 데이터와 클러스터에 의해 데이터가 클러스터 내에 있다면 1, 아니면 0의 값 출력
- 변화량에 대한 허용 오차값이 이정 수준내로 들어온다면 더이상 클러스터가 변화하지 않는다는 것이고, 최적화가 완료되었다는 것
- 점들간의 단위와 변동폭이 크다면 왜곡 발생확률 증가 => 표준화
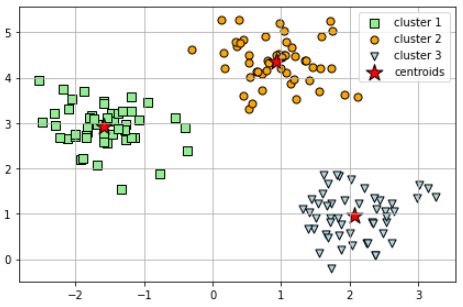
KMEAN 그래프구현 예제
- 클러스터 내의 제곱 오차합 (SSE)을 반복적으로 최소화
- 단점
-
센트로이드를 랜덤으로 지정해서 예초에 잘못선정된 곳에서 시작
클러스터가 적은 곳에서 시작하면 클러스터의 성능이 불안전해짐 고차원의 데이터에서 위험 부담이 높다 - 클러스터가 중첩 X
- 계층적 X
- 클러스터당 하나 이상의 데이터가 존재한다고 가정
-
3. k-means++
- k-means의 무작위 성을 보와하기 위한 기법
- 현명한 초기 센트로이드 할당
- 초기 센트로이드가 멀리 떨어지도록 구현 => 일관됨
4. 비지도학습 성능 평가 기법
- 지도학습의 성능평가 기법을 적용할 수 없다
1. 사이킷런
- 알고리즘 자체의 지표를 사용
- 클러스터 내 오차 제곱합(SSE)
2. 엘보우방법
- 최적의 클러스터 수를 추정할 수 있다.
- k값의 증가 => 센트로이드 증가 => 데이터가 센트로이드에 더 가까워 지는 것 => 왜곡값(SSE)의 감소
- 왜곡이 빠르게 증가하는 K값을 찾는것이 목표
엘로우방법 그래프구현 예제
3. 실루엣 그래프
클러스터 내 데이터들이 얼마나 조밀하게 모여있는지를 측정하는 그래프 도구
- 다양한 군집 알고리즘에 적용가능
- 순서
- 하나의 임의의 데이터(x)와 동일한 클러스터내의 모든 다른 데이터 포인트 사이의 거리를 평균하여 클러스터 응집력(a)을 계산합니다.
- 앞서 선정한 데이터와 가장 가까운 클러스터의 모든 샘플간 평균 거리로 최근접 클러스터의 클러스터 분리도C를 계산합니다.
- 클러스터 응집력과 분리도 사이의 차이를 둘 중 큰값으로 나눠 실루엣 계수(s)를 계산합니다
- 분리력>응집력 이상적인 실루엣 계수 1
- 응집력이 작을수록 클러스터내 다른 데이터들과 비슷하다는 뜻
5. 계층 군집
- 덴드로그램(Dendrogram)
- 의미 있는 분류 체계
- 클러스트의 수를 미리 지정하지 않아도 된다.
1. 병합 계층 군집
- 클러스터당 하나의 데이터에서 시작해서 모든 데이터가 하나의 클러스터에 속할 때까지 가장 가까운 클러스터를 병합해 나감
1. 단일 연결
- 클러스터 쌍에서 가장 비슷한 데이터 간의 거리를 계산
- 거리의 값이 가장 가까운 두 클러스터를 하나로 병합
2. 완전 연결(기본)
- 클러스터 쌍에서 가장 멀리 있는 데이터를 찾아 거리를 구한 후 가장 가까운 두 클러스터를 합친다.
- 동작 순서
- 모든 데이터의 거리행렬을 계산합니다.
- 모든 데이터 포인트를 단일 클러스터로 표현합니다.
- 가장 비슷하지 않은 즉, 멀리 떨어진 데이터 간 거리에 기초하여 가장 가까운 두 클러스터를 하나로 합쳐줍니다.
- 유사도 행렬 업데이트
- 하나의 클러스터가 남을 때 까지 2~4단계 반복.
3. 평균 연결
- 두 클러스터에 있는 모든 샘플 사이의 평균 거리가 가장 작은 클러스터 쌍을 합친다.
4. 와드 연결
- 제곱 오차합(SSE)가 가장 작게 증가하는 두 클러스터를 합치는 방식
2. 분할 계층 군집
-
하나의 클러스터에서 시작해 클러스터에 하나의 데이터가 있을때까지 반복적으로 데이터를 나눈다
-
히트맵
- 히트맵과 덴드로그햄이 함께 쓰이게 되면 데이터 행렬의 기본값을 색으로 표현할 수 있게 되고 각 데이터셋을 효과적으로 요약할 수 있다.
6. 밀집도 기반 군집(DBSCAN)
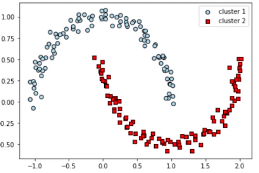
- 원형 클러스트를 가정하지 않는다.
- 자연스럽게 이상치 데이터들을 구분할 수 있다.
- 복잡한 구조를 가진 데이터 셋을 구분하는데 있어, 그 능력이 출중하다
- 밀집도 : 특정반경ε(엡실론) 안에 있는 샘플의 개수(MinPts)로 정의
- 어떠한 데이터 특정 반경 안에 있는 이웃점이 우리가 임의로 지정한 개수 이상이면 이 데이터는 중심점이 된다.
- 다음으로 가장 가까운점 기준, 특정반경 이내에 지정된 개수보다 이웃은 적지만 다른 중심점의 반경안에 있으면 경계점이다.
- 이러한 방식으로 점들을 할당하고 나서 그 어떠한 점에도 속하지 않는 모든 점들은 이상치가 된다.
- 중심점(core point)
- 경계점(border point)
- 이상치(noise point)
- 중심점이 다른 중심점에 포함되면 두 군집은 하나의 군집으로 연결한다.
- 단점
- 데이터의 특성이 늘어남에 따라 차원의 저주로 인한 역효과
- 차원축소, 표준화 필요
- eps와 min_samples를 최적화 해야한다.
Leave a comment