
강화학습
Updated:
1. 강화학습
- 정답이 없고 비지도 학습처럼 데이터만을 기반으로 학습하지 않는다
- 에어전트(Agent)가 환경과 상호작용
- 행동과 보상의 반복
- 보상을 최대화하는 방향으로 학습
- 강화학습의 학습과정
- 페널티 => 보상
- 다수의 시행착오
- 비교적 명확한 보상을 설정할 수 있는 문제를 해결하는데 사용
- ex)AlphaGo
- 보상을 최대화하는 의사결정 전략 => 순차적인 행동들을 알아나가는 방법 => (MDP)Markov decision process
1. MDP
순차적인 행동들을 알아나가는 방법
- 상태 변화 확률, 감가율, 행동, 상태, 보상 함수
1. 에이전트
- 의사결정
2. 환경
- 에이전트의 의사결정 반영
- 정보전달
3. 상태
- 에이전트가 의사결정을 하기 위해 필요한것
- 관측값, 행동, 보상을 가공한 정보
4. 행동
- 에어전트가 의사결정을 한후 취할 수 있는 행동
- 이산적 행동
- 행동의 선택지가 있고 그중하나 선택
- 연속적 행동
- 선택지마다 특정값을 수치로 입력하고 입력된 값만큼 행동
5. 관측
- 환경에서 전달된 정보
- 시각적 관측
- 현재 상태의 정보를 이미지로 표현한 것
- 수치적 관측
- 수치로만 표현한 것
6. 보상함수

- 특정상태에서 특정행동을 했을때 보상
- 이 보상을 통해 학습 진행
2. 학습과정
- 에피소드가 지나왔던 상태에서 했던 행동에 대한 정보를 기록
- 그 정보를 이용하여 다음 에피소드에 대한 의사결정
- 반복
- 현대 스텝에서 받았던 보상으로 부터 에피소드가 끝날때 까지 받았던 보상들을 더한 것을 정보로 이용
3. 감가율(γ)
- 0~1사이의 값
- 1에 가까울 수록 미래의 보상에 더 많은 가중치
- 보상값
- 반환값(G)를 사용하여 표기
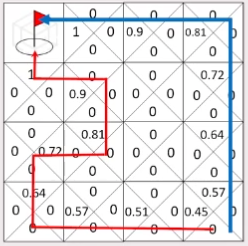

- 반환값(G)를 사용하여 표기
- 미리 찾은 경로를 모르는 길보다 괜찮다고 판단하기 때문에 탐험을 사용
4. 탐험(무작위 움직임 - Exploration)
- 이미 찾은 길로만 가지 않도록 여러경로를 시험해보게 한다.
- 많은 경험을 해보는것이 중요
- 무작위 탐색 방법
5. 익숙한 움직임(이용, 활용 - Exploitation)
- 탐험과 대립된다.
2. 활용과 탐험
- 활용(탐욕적)
- 학습된 결과에 따라 에이전트의 행동을 결정하는 기법
- 탐욕적 방법
- 가장 큰 보상을 주는것을 선택
- 장기적으로 보상의 총합을 키우기 위해서는 탐험이 좋은 선택
- 활용과 탐험 사이 => 불확실한 판단
- 활용과 탐험의 딜레마, 갈등
- 장기적으로는 탐험이 효율적
- 활용을 할 것인지 탐험을 할것인지 결정
- 정밀한 가치 추정값
- 불확실성
- 앞으로 남아있는 단계의 개수
- 복잡한 방법으로 결정됨
- 활용과 탐험을 적절히 분배하여 균형을 유지
- 강화학습에서 나타나는 독특한 어려움
1. 행동가치방법
- 행동의 가치를 추정하고 추정값을 통해 행동을 선택
- 가장 간단한 행동 선택 규칙은 추정 가치가 최대인 행동 중 하나를 선택하는 것이다
- 현재의 지식 사용이 항상 포함
1. 입실론 탐욕적방법
- 대부분은 탐욕적으로 선택하고 아주 가끔 상대적 빈도수를 작은 값으로 유지하면서 모든 행동을 대상으로 무작위 선택
- 모든 행동이 선택될 확률은 균등하며 행동 선택은 행동 가치 추정과는 무관하게 이루어진다
Leave a comment