
실습_2. 논리적인 자료의 요약
Updated:
| 카페 | 카페인 함량 | 카페 | 카페인 함량 |
|---|---|---|---|
| 커피빈 | 202 | 빽다방 | 177 |
| 스타벅스 | 121 | 할리스 | 148 |
| 이디야 | 89 | 동네카페 | 121 |
| 투썸플레이스 | 137 | 엔제리너스 | 158 |
import numpy as np
from scipy import stats
coffee = np.array([202,177,121,148,89,121,137,158])
중심위치의 측도 : 평균
#평균계산
cf_mean = np.mean(coffee)
중심위치의 측도 : 중앙값
#중앙값 계산
cf_median = np.median(coffee)
중심위치의 측도 : 최빈값
#최빈값 계산
cf_mode = stats.mode(coffee)
#퍼진 정도의 측도 : 분산
#분산 계산
cf_var = variance(coffee)
퍼진 정도의 측도 : 표준편차
#표준편차 계산
cf_std = stdev(coffee)
퍼진 정도의 측도 : 범위
#범위 계산
cf_range = np.max(coffee) - np.min(coffee)
퍼진 정도의 측도 : 백분위수
#백분위수
cf_quant_20 = np.percentile(coffee, 20)
cf_quant_80 = np.percentile(coffee, 80)
퍼진 정도의 측도 : 사분위수 범위
#IQR
q75, q25 = np.percentile(coffee,[75,25])
cf_IQR = q75-q25
퍼진 정도의 측도 : 변동계수
cf_cv = stdev(coffee)/np.mean(coffee)
cf_cv = round(cf_cv,2)
수치형 자료의 요약 : 도수분포표
주량 데이터 drink_cup의 도수 분포표를 그려보도록 하겠습니다.
1장에서는 참석 여부를 나타내는 범주형 자료의 도수 분포표를 그렸었는데요,
이번에는 수치형 자료인 “주량”으로 도수 분포표를 그려보도록 하겠습니다.
우선 print 문을 사용해서 데이터를 출력해 확인해보세요.
-
도수분포표 연속형 자료로 도수분포표를 만드려면 우선 구간을 나눠야 합니다. 이 구간을 계급이라고도 부릅니다. 저희는 주량 데이터를 4그룹으로 나눠보겠습니다.
- factor_cup에 drink_cup 데이터의 cup으로 4개 범위를 쪼개어 저장해보겠습니다.
factor_cup = pd.cut(drink_cup.cup, 4)
- factor_cup 으로 그룹을 만들어 group_cup 에 저장해보겠습니다.
group_cup = drink_cup['cup'].groupby(factor_cup)
- 이 그룹별로 도수를 계산해 count_cup 에 저장해 출력해보겠습니다.
count_cup = group_cup.agg(['count'])
import numpy as np
import pandas as pd
# 주량 데이터
drink_cup = pd.DataFrame({'cup' :[22,7,19,3,10,8,19,7,15,9,35,5],'who' : [ 'A', 'E', 'D', 'B', 'C','A','A','A','D','B', 'C','B']})
print(drink_cup)
# 도수분포표
factor_cup = pd.cut(drink_cup.cup,4)
group_cup = drink_cup['cup'].groupby(factor_cup)
count_cup = group_cup.agg(['count'])
print(count_cup)
- 결과
cup who
0 22 A
1 7 E
2 19 D
3 3 B
4 10 C
5 8 A
6 19 A
7 7 A
8 15 D
9 9 B
10 35 C
11 5 B
count
cup
(2.968, 11.0] 7
(11.0, 19.0] 3
(19.0, 27.0] 1
(27.0, 35.0] 1
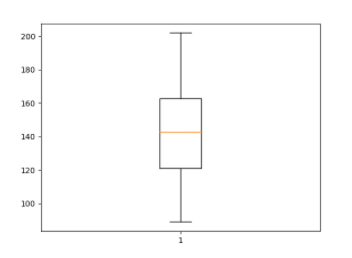
수치를 통한 연속형 자료의 요약 : 상자그림
| 카페 | 카페인 함량 | 카페 | 카페인 함량 |
|---|---|---|---|
| 커피빈 | 202 | 빽다방 | 177 |
| 스타벅스 | 121 | 할리스 | 148 |
| 이디야 | 89 | 동네카페 | 121 |
| 투썸플레이스 | 137 | 엔제리너스 | 158 |
from elice_utils import EliceUtils
import numpy as np
import matplotlib.pyplot as plt
elice_utils = EliceUtils()
#카페인 함유량
coffee = np.array([202,177,121,148,89,121,137,158])
#상자그림
fig, ax = plt.subplots()
## 여기에 코드를 작성해주세요
plt.boxplot(coffee)
##
plt.show()
fig.savefig("box_plot.png")
elice_utils.send_image("box_plot.png")
- 결과
두 범주형 변수의 요약 : 분할표
두 범주형 변수를 요약할 수 있는 분할표를 만들어보겠습니다. mart.csv데이터에는 거주 지역region, 가족 구성원 수 family_num, 마트명 mart 이 있습니다. 이를 활용하여 지역별로 선호하는 마트, 가족구성원의 수별로 선호하는 마트에 대해 알아보겠습니다.
- 지역별로 선호하는 마트 지역별로 어느 마트를 선호하는지 확인하기 위해 분할표를 만들어 region_crosstab 에 저장해 확인해보겠습니다.
region_crosstab = pd.crosstab(mart['region'],mart['mart'])
- 가족구성원의 수별로 선호하는 마트 가족구성원의 수에 따라 어느 마트를 선호하는지 확인하기 위해 분할표를 만들어 #Q2 아래에 famnum_crosstab 에 저장해 확인해보겠습니다.
famnum_crosstab = pd.crosstab(mart['family_num'],mart['mart'])
import numpy as np
import pandas as pd
import matplotlib as plt
# 데이터 불러오기
mart = pd.read_csv("mart.csv")
print(mart)
# Q1.지역별로 선호하는 마트
region_crosstab = pd.crosstab(mart['region'],mart['mart'])
print(region_crosstab)
# Q2. 가족구성원의 수별로 선호하는 마트
famnum_crosstab = pd.crosstab(mart['family_num'],mart['mart'])
print(famnum_crosstab)
index region family_num mart
0 1 gyeongsang 2 lotte
1 2 gangwon 2 lotte
2 3 gyonggi 2 emart
3 4 gyeongsang 3 lotte
4 5 chungcheong 4 homeplus
5 6 chungcheong 1 costco
6 7 seoul 4 costco
7 8 jeolla 1 homeplus
8 9 seoul 3 homeplus
9 10 chungcheong 4 emart
10 11 gyonggi 2 emart
11 12 gangwon 2 homeplus
12 13 gyeongsang 5 lotte
13 14 chungcheong 5 costco
14 15 gangwon 2 homeplus
15 16 seoul 3 homeplus
16 17 jeolla 3 costco
17 18 gyonggi 1 homeplus
18 19 jeolla 2 homeplus
19 20 jeolla 4 costco
20 21 gyonggi 4 emart
21 22 jeolla 3 emart
22 23 gangwon 1 emart
23 24 seoul 4 emart
24 25 chungcheong 3 costco
25 26 gyonggi 2 emart
26 27 gangwon 3 homeplus
27 28 gyonggi 5 lotte
28 29 gyonggi 2 lotte
29 30 gangwon 5 emart
30 31 jeolla 4 homeplus
31 32 seoul 1 homeplus
32 33 chungcheong 2 lotte
33 34 seoul 2 costco
34 35 gangwon 1 emart
35 36 gangwon 2 costco
36 37 gangwon 3 lotte
37 38 jeolla 5 emart
38 39 seoul 4 lotte
39 40 gyonggi 1 homeplus
40 41 gyeongsang 4 lotte
41 42 gyeongsang 4 homeplus
42 43 gyeongsang 4 lotte
43 44 chungcheong 1 emart
44 45 gyeongsang 5 lotte
45 46 gyeongsang 2 lotte
46 47 gyeongsang 1 homeplus
47 48 seoul 1 emart
48 49 gyeongsang 2 emart
49 50 gyonggi 1 lotte
mart costco emart homeplus lotte
region
chungcheong 3 2 1 1
gangwon 1 3 3 2
gyeongsang 0 1 2 7
gyonggi 0 4 2 3
jeolla 2 2 3 0
seoul 2 2 3 1
mart costco emart homeplus lotte
family_num
1 1 4 5 1
2 2 4 3 5
3 2 1 3 2
4 2 3 3 3
5 1 2 0 3
두 수치형 변수의 요약 : 산점도
body.csv 파일에는 한 사람의 20년 신체 기록이 담겨있습니다. 키height, 몸무게 weight, 골격근량 muscle_mass, 체지방량 body_fat , 다리길이 leglen, 모발 hair 이 들어있습니다.
이를 가지고 두 연속형 변수의 관계를 요약해보겠습니다. 가장 직관적이고 한눈에 상관계수를 파악할 수 있는 산점도를 그려보겠습니다.
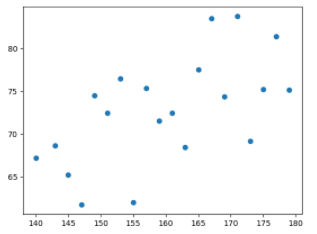
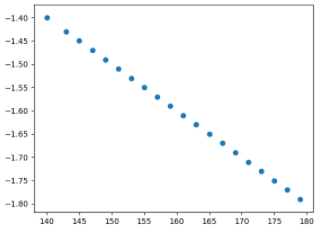
- 키와 몸무게의 관계
스크립트의 Q1 1-1에 키와 몸무게와의 관계를 볼 수 있는 산점도 코드를 작성하여 그려보세요.
plt.scatter(body['height'], body['weight'])
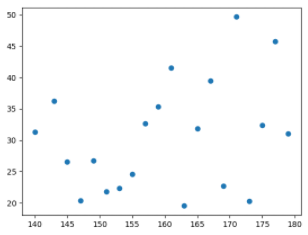
- 키와 체지방량의 관계
이를 응용하여 스크립트의 Q1 1-2에 키와 체지방량의 관계를 볼 수 있는 산점도 코드를 작성하여 그려보세요.
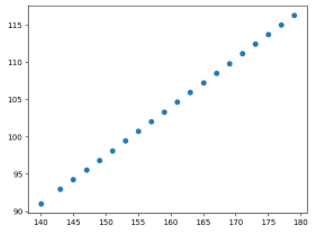
- 키와 다리길이의 관계
스크립트의 Q1 1-3에 키와 다리길이의 관계를 볼 수 있는 산점도 코드를 작성하여 그려보세요.
- 키와 모발의 관계
스크립트의 Q1 1-4에 키와 모발의 관계를 볼 수 있는 산점도 코드를 작성하여 그려보세요.
두 수치형 변수의 요약 : 공분산
body.csv 파일에는 한 사람의 20년 신체 기록이 담겨있습니다. 키height, 몸무게 weight, 골격근량 muscle_mass, 체지방량 body_fat , 다이길이 leglen, 모발 hair 이 들어있습니다.
산점도에서 본 직관적인 관계가 맞는지 직접 수치로 계산하여 공분산으로 판단해보겠습니다.
공분산 전체의 공분산을 계산해보고 cov_body에 저장해보겠습니다.
cov_body = body.cov()
from statistics import variance, stdev
import numpy as np
import pandas as pd
# body.csv 읽어오기
body = pd.read_csv("body.csv")
# 공분산
cov_body = body.cov()
print(cov_body)
height weight ... leglen hair
height 142.050000 44.607316 ... 92.332500 -1.420500
weight 44.607316 1144.833587 ... 28.994755 -0.446073
muscle_mass 11.784461 8.641430 ... 7.659900 -0.117845
body_fat 32.980749 34.839548 ... 21.437487 -0.329807
leglen 92.332500 28.994755 ... 60.016125 -0.923325
hair -1.420500 -0.446073 ... -0.923325 0.014205
[6 rows x 6 columns]
두 수치형 변수의 요약 : 상관계수
body.csv 파일에는 한 사람의 20년 신체 기록이 담겨있습니다. 키height, 몸무게 weight, 골격근량 muscle_mass, 체지방량 body_fat , 다이길이 leglen, 모발 hair 이 들어있습니다.
산점도에서 본 직관적인 관계가 맞는지 직접 수치로 계산하여 상관계수로 판단해보겠습니다.
상관계수 전체의 상관계수를 계산하여 corr_body 에 저장해보겠습니다.
corr_body = body.corr()
[실습6] 에서 그려보았던 산점도에서 본 직관적인 관계가 맞는지 직접 수치로 확인해보세요.
키와 몸무게의 관계 : 우 상향 직선, 기울기가 양수인 경향의 직선 키와 체지방량의 관계 : 우 하향 직선, 기울기가 음수인 경향의 직선 키와 다리 길이의 관계 : 모든 점이 정확히 기울기가 양수인 직선 키와 모발의 관계 : 모든 점이 정확히 기울기가 음수인 직선
from statistics import variance, stdev
import numpy as np
import pandas as pd
# body.csv 읽어오기
body = pd.read_csv("body.csv")
# 상관계수
corr_body = body.corr()
print(corr_body)
height weight ... leglen hair
height 1.000000 0.596670 ... 1.000000 -1.000000
weight 0.596670 1.000000 ... 0.596670 -0.596670
muscle_mass 0.156690 0.218316 ... 0.156690 -0.156690
body_fat 0.315368 0.632993 ... 0.315368 -0.315368
leglen 1.000000 0.596670 ... 1.000000 -1.000000
hair -1.000000 -0.596670 ... -1.000000 1.000000
[6 rows x 6 columns]
Leave a comment