
실습_3. API를 이용한 크롤링
Updated:
Daum 증권 페이지에서 주가 크롤링
- 다음과 같은 방법으로 API url을 찾는다
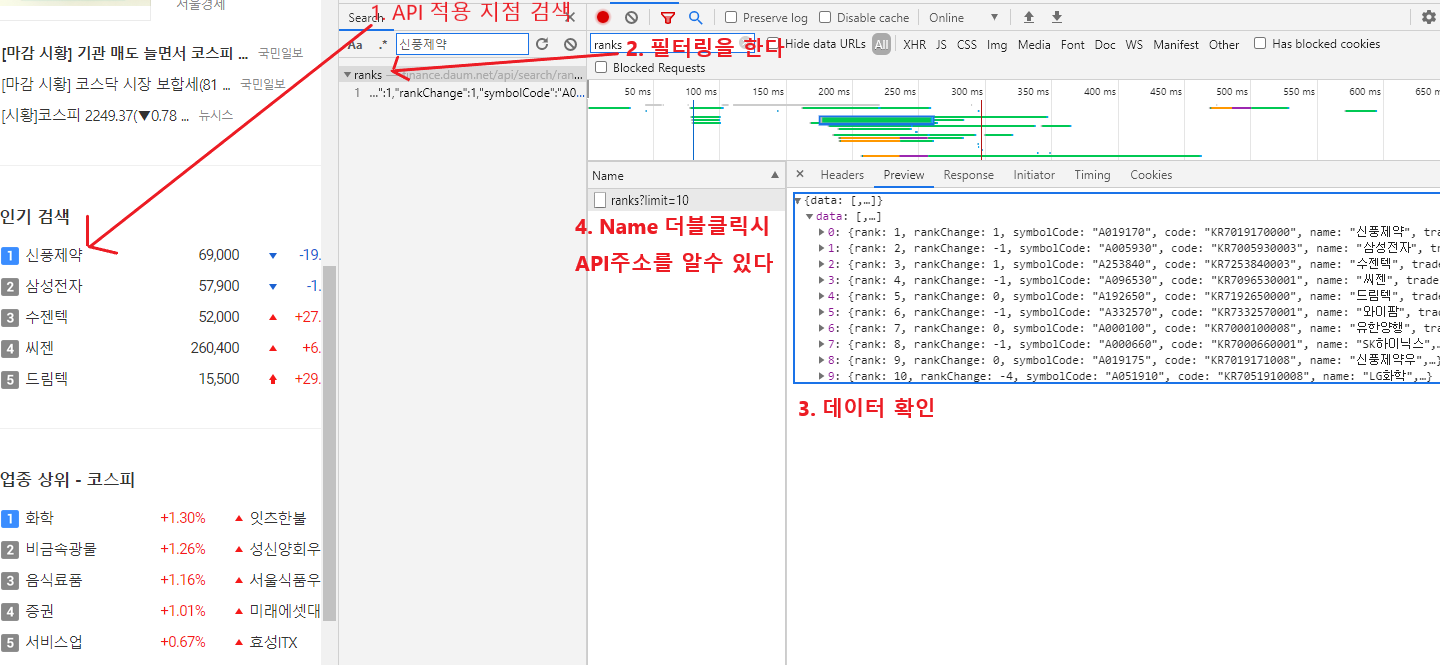
import requests
import json
custom_header = {
'referer' : 'http://http://finance.daum.net/quotes/A048410#home',
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' }
def get_data() :
result = []
url = "http://finance.daum.net/api/search/ranks?limit=10"
# 상위 10개 기업의 정보를 얻는 API url을 작성
req = requests.get(url, headers = custom_header)
if req.status_code == requests.codes.ok:
print("접속 성공")
# API에 접속에 성공하였을 때의 logic을 작성
# JSON 데이터의 원하는 부분만 불러와 result에 저장
# ========================================================
stock_data = json.loads(req.text)
# stock_data에 json파일을 json.loads해서 담아준다
# ========================================================
for i in stock_data['data']:
result.append([i['rank'], i['name'], i['tradePrice']])
else:
print("접속 실패")
return result
def main() :
data = get_data()
for d in data :
print(d)
if __name__ == "__main__" :
main()
네이버 실시간 검색어 크롤링
import requests
import json #json import하기
#custom_header을 통해 아닌 것 처럼 위장하기
custom_header = {
'referer' : 'https://www.naver.com/',
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' }
def get_keyword_ranking() :
result = []
url = "https://apis.naver.com/mobile_main/srchrank/srchrank?frm=main&ag=20s&gr=4&ma=-2&si=2&en=2&sp=-2"
req = requests.get(url, headers = custom_header)
if req.status_code == requests.codes.ok:
print("접속 성공")
stock_str = json.loads(req.text)
for i in stock_str["data"]:
result.append([i['keyword'],i['keyword_synonyms']])
else:
print("Error code")
return result
def main() :
result = get_keyword_ranking()
i = 1
for keyword, synonyms in result :
if synonyms :
print(f"{i}번째 검색어 : {keyword}, 연관검색어 : {synonyms}")
else :
print(f"{i}번째 검색어 : {keyword}")
i += 1
if __name__ == "__main__" :
main()
음식점 리뷰 크롤링
- 원하는 음식점의 하이퍼링크를 찾아서 리뷰를 확인한다.
- while 문을 사용해서 음식점이 가지고 있는 모든 리뷰를
from bs4 import BeautifulSoup
import requests
import json
custom_header = {
'referer' : 'https://www.mangoplate.com',
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' }
def get_reviews(code) :
comments = []
i = 0
while True :
url = f"https://stage.mangoplate.com/api/v5{code}/reviews.json?language=kor&device_uuid=V3QHS15862342340433605ldDed&device_type=web&start_index={i}&request_count=5&sort_by=2"
# 0으로 초기화 되어있는 start_index를 반복을 통해서 계속 받아와 준다
req = requests.get(url, headers = custom_header)
if req.status_code == requests.codes.ok:
print("접속 성공")
stock_str = json.loads(req.text)
if len(stock_str) == 0:
break
for re in stock_str:
comments.append(re['comment']['comment'])
else:
print("Error code")
i = i + 5
return comments
def main() :
href = "/restaurants/iMRRP69qtkeO"
# 리뷰를 보고싶은 음식점의 하이퍼링크를 넣어준다
print(get_reviews(href))
if __name__ == "__main__" :
main()
음식점 href 크롤링
- 검색후 해당 되는 음식점 href
from bs4 import BeautifulSoup
import requests
import json #json import하기
custom_header = {
'referer' : 'https://www.mangoplate.com/',
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' }
def get_restaurants(name) :
# 검색어 name이 들어왔을 때 검색 결과로 나타나는 식당들을 리스트에 담아 반환
restuarant_list = []
url = "https://www.mangoplate.com/search/" + name
req = requests.get(url, headers = custom_header)
soup = BeautifulSoup(req.text, "html.parser")
div = soup.find_all("div",class_="info")
for re in div:
href = re.find("a")['href']
title = re.find("h2",class_="title").get_text().replace("\n","").replace(" ","")
restuarant_list.append([href,title])
return restuarant_list
def main() :
name = input()
restuarant_list = get_restaurants(name)
print(restuarant_list)
if __name__ == "__main__" :
main()
검색 결과 음식점 리뷰 크롤링
from bs4 import BeautifulSoup
import requests
import json #json import하기
custom_header = {
'referer' : 'https://www.mangoplate.com/',
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' }
def get_reviews(code) :
comments = []
url = f"https://stage.mangoplate.com/api/v5{code}/reviews.json?language=kor&device_uuid=V3QHS15862342340433605ldDed&device_type=web&start_index=0&request_count=5&sort_by=2"
req = requests.get(url, headers = custom_header)
if req.status_code == requests.codes.ok:
result = []
print("접속 성공")
reviews = json.loads(req.text)
for i in range(5):
result.append(reviews[i]["comment"]["comment"][:20].replace("\n",""))
else:
print("Error code")
# req에 데이터를 불러온 결과가 저장되어 있습니다.
# JSON으로 저장된 데이터에서 댓글을 추출하여 comments에 저장하고 반환하세요.
return result
def get_restaurants(name) :
url = f"https://www.mangoplate.com/search/{name}"
req = requests.get(url, headers = custom_header)
soup = BeautifulSoup(req.text, "html.parser")
# soup에는 특정 키워드로 검색한 결과의 HTML이 담겨 있습니다.
result = []
restaurants = soup.find_all("div",class_="info")
# 특정 키워드와 관련된 음식점의 이름과 href를 튜플로 저장하고,
for res in restaurants:
name = res.find("h2",class_="title").get_text().replace("\n","").replace(" ","")
a_tag = res.find("a")["href"]
result.append((name,a_tag))
# 이름과 href를 담은 튜플들이 담긴 리스트를 반환하세요.
return result
def main() :
name = input("검색어를 입력하세요 : ")
restuarant_list = get_restaurants(name)
for r in restuarant_list :
print(r[0])
print(get_reviews(r[1]))
print("="*30)
print("\n"*2)
if __name__ == "__main__" :
main()
Leave a comment